The SIAM conference on Applied Algebraic Geometry took place in Eindhoven last week.
The “mini symposia” included:
- Applications of Algebraic Geometry to Post-Quantum Cryptology
- Elliptic Curves and Pairings in Cryptography
- Applications of Isogenies in Cryptography
Despite having promised myself to attend talks outside of my domain, I ended up attending all the talks in the “Applications of Algebraic Geometry to Post-Quantum Cryptology” mini-symposium. The first day was mostly about multi-variate crypto. Bo-Yin Yang gave two talks about the recent history of attacks on multivariate schemes, and some insights into the new UOV and TUOV submissions to NIST’s on-ramp signature call. The rest of the talks was about cryptanalysis. The day was closed by something more palatable to the audience of this blog and my personal highlight of the conference: Guido Lido took over Giulio Codogni’s spot and delivered a spectacular double talk on the spectral properties of isogeny graphs with level structure. At Eurocrypt, Guido and coauthors had shown that supersingular isogeny graphs with Borel level structure are Ramanujan, and applied this to construct statistically zero-knowledge proofs of isogeny knowledge. Here Guido and Giulio generalize the result to arbitrary level structures, showing that, modulo an obstruction coming from the Weil pairing, they are all “somewhat Ramanujan”. Guido barely said “crypto”, mistook the audience for the SGA seminar, and took us along in a journey through modular curves and Hecke operators that was easily the most AG talk in SIAM AG!
The second day was nearly all isogenies, and very much Italian. I essentially remade Guido’s talk for the layman, presenting along the way a still unpublished attack against “SIDH with a single torsion point”. Federico Pintore followed up with hard facts and numbers on still-unbroken SIDH-like signatures: nothing NIST-worthy, but some good cleanup. Annamaria Iezzi presented some progress on computing the endomorphism ring of supersingular curves: nothing new complexity-wise, but some heuristics are removed. Unfortunately I missed Valerie Gilchrist’s talk on supsersingularity testing. Thomas Decru presented his attack on SIDH, I don’t suppose the readers of this blog need to know more about this. Boris Fouotsa presented some counter-measures against the SIDH attacks that appeared at the last Eurocrypt, and then presented some nice improvements using what he calls “artificial orientations” (which, by the end of the symposium, everyone understood as being nothing else than Cartan level structures). Wouter Castryck gave the only non-isogeny talk of the day: he presented an attack against a key-exchange scheme based on “disguised” Veronese varieties, that one would be tempted to classify into the multi-variate bucket. The attack uses what Wouter calls “the Lie algebra method”; as he puts it: it’s all linear algebra, although quite advanced one.
The audience of the blog would certainly have found the workshop “Elliptic Curves and Pairing in Cryptography” interesting, however I attended other workshops, so I cannot report on it.
The week was closed by the well attended “Applications of Isogenies in Cryptography” workshop. The quick summary is: 50% SQIsign, 50% isogenies of abelian surfaces, and a vanishingly small set of other stuff.
Michael Meyer presented the state of the art on generating SQIsign-friendly primes and reported on the searches that have been run for the current NIST submission. Lorenz Panny and Antonin Leroux gave nice presentations on the effective Deuring correspondence, both in the general case and in the specific case of SQIsign. When asked how optimistic he is about SQIsign’s potential for standardization, Antonin gave a pretty pessimistic answer. Benjamin Wesolowski came to the rescue giving the audience some hope back with his presentation on SQIsignHD, the SIDH-attacks-based variant of SQIsign that promises much simpler and faster (and slightly shorter) signatures at the cost of a considerably more complex verification. Gustavo Banegas explained how to implement all of this in (maybe) constant time. Continuing on the “using SIDH attacks for good” topic, we had talks by Giacomo Pope on algorithms for computing isogenies between products of elliptic curves, and by Luciano Maino on using the SIDH attacks for making a PKE scheme named FESTA.
In the vanishingly small set, Peter Kutas gave a nice talk on a quantum break of pSIDH, an obscure (and totally impractical) key exchange that had always looked too risky to be true. More than by the breaking of pSIDH, I was impressed by the underlying technique. In past work, Peter and coauthors had defined a group action of GL₂ on the set of j-invariants at a certain distance from a starting curve, and used that to give a subexponential quantum attack (essentially, Kuperberg) on overstretched variants of SIDH. I wasn’t impressed at the time, given that we already had classical attacks on overstretched SIDH. What’s new is that Peter & co. found a way to express the problem of breaking pSIDH as a hidden subgroup problem, where the ambient group is GL₂ and the hidden subgroup is a Borel subgroup. By sheer coincidence, this non-abelian HSP turns out to be solvable in quantum polynomial time! Interestingly, the same idea would apply to SIDH and M-SIDH too if only they contained enough torsion point information (pSIDH contains an arbitrary amount of torsion point information, and seems to have been invented on purpose to make this attack possible!). To me, this is a strong indication that M-SIDH should be set up with a starting curve of unknown endomorphism ring.
For a change of scenery, Ward Beullens presented his attacks on signature schemes based on alternating trilinear forms. The only connection with isogenies seems to be the appearance of nice volcano-like graphs when studying the case of dimension 9 (one among many parameter sets), however the explanation appears to have more to do with an abelian surface acting on some bilinear forms.
But all of the above can be easily found on eprint, and the audience of the blog was probably already familiar with many of the results. The surprise of the workshop were the talks by David Kohel and Chloe Martindale. Both reported on work in progress and in both cases the audience was left with a feeling that, despite the beautiful theory, some fundamental ingredient is still missing.
David talked about formal orientations of elliptic curves. In the spirit of his and Leonardo Colò’s pioneering work on orienting supersingular elliptic curves, they are now trying to give a sense to, and possibly make cryptography out of, attaching some endomorphism ring information to the formal group of an elliptic curve. The algebra looks quite different from what we have been used to so far, as there is essentially a unique endomorphism ring for all curves. David concluded on a rather disconsolate note, arguing that all useful information seems to be extremely hard to compute.
Chloe presented ideas about recasting SQIsign in the framework of Bruhat-Tits trees. Although most of it is about using different terminology for the same objects that appear in the Deuring correspondence, her hope is to push much of the complexity of SQIsign into the key generation, making signing blazing fast. However, she and Ross Bowden appear to be stuck at some lattice problem that would let them describe the way the Bruhat-Tits tree folds, and sent a cry for help.
Overall, SIAM AG was intense and fun, remaining one of my favorite conferences. There exist video recordings of all the sessions, and you may get a hand on them if you ask the speakers politely (I don’t think we were asked for authorization to publish, so I don’t expect them to ever become available on youtube, unfortunately).
— Luca De Feo

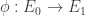

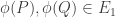

![E_0[B]](https://s0.wp.com/latex.php?latex=E_0%5BB%5D&bg=ffffff&fg=333333&s=0&c=20201002)
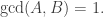

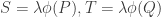


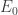

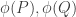
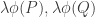

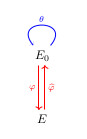
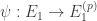
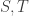

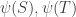
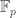


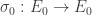

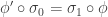
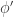
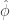

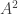
![R \in E_1[A]](https://s0.wp.com/latex.php?latex=R+%5Cin+E_1%5BA%5D&bg=ffffff&fg=333333&s=0&c=20201002)
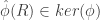
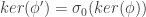
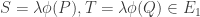
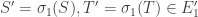
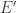
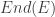
 , the group
, the group  is the ideal class group of the quadratic field
is the ideal class group of the quadratic field 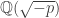 , and the group acts on the set
, and the group acts on the set  of supersingular elliptic curves with
of supersingular elliptic curves with  -invariant in the finite field
-invariant in the finite field  . I hope readers will enjoy some of the constructive and simple proofs in the note.
. I hope readers will enjoy some of the constructive and simple proofs in the note. . There is a natural analogue of the Discrete Logarithm problem: Given
. There is a natural analogue of the Discrete Logarithm problem: Given  and
and  . There is also an analogue of the Diffie-Hellman problem: Given
. There is also an analogue of the Diffie-Hellman problem: Given 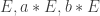 to compute
to compute  . If this problem is hard then we have a Diffie-Hellman protocol as follows: Alice chooses
. If this problem is hard then we have a Diffie-Hellman protocol as follows: Alice chooses 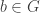 and sends
and sends 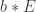 to Alice. Then both of them can compute
to Alice. Then both of them can compute  for uniformly sampled
for uniformly sampled 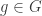 ) but from CSIDH we get REGA (which allows to efficiently compute
) but from CSIDH we get REGA (which allows to efficiently compute 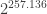 . Knowing the class group structure one has an EGA and a secure signature scheme. (This blog post is about CSIDH, so I do not mention SQISign.)
. Knowing the class group structure one has an EGA and a secure signature scheme. (This blog post is about CSIDH, so I do not mention SQISign.)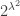 , where
, where 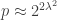 . (These choices may be excessively large, but they are a conservative choice.)
. (These choices may be excessively large, but they are a conservative choice.)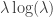 ,
, 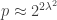 , and exponents of size
, and exponents of size 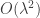 . Giving total complexity
. Giving total complexity 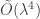 operations in
operations in 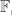 , which is
, which is 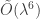 bit operations for one group action. The total sign/verify time for SeaSign is
bit operations for one group action. The total sign/verify time for SeaSign is  bit operations, since the protocol has to be repeated
bit operations, since the protocol has to be repeated  be a point on an elliptic curve of prime order
be a point on an elliptic curve of prime order  . The Computational Diffie-Hellman (CDH) problem is: Given points
. The Computational Diffie-Hellman (CDH) problem is: Given points ![(P, [a]P, [b]P)](https://s0.wp.com/latex.php?latex=%28P%2C+%5Ba%5DP%2C+%5Bb%5DP%29&bg=ffffff&fg=333333&s=0&c=20201002) to compute
to compute ![[ab]P](https://s0.wp.com/latex.php?latex=%5Bab%5DP&bg=ffffff&fg=333333&s=0&c=20201002) . This computational assumption underlies many elliptic curve cryptosystems, especially those based on key exchange or encryption.
. This computational assumption underlies many elliptic curve cryptosystems, especially those based on key exchange or encryption.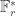 . The idea was further developed by Maurer (CRYPTO 1994), who replaced the “auxiliary group” with an elliptic curve over
. The idea was further developed by Maurer (CRYPTO 1994), who replaced the “auxiliary group” with an elliptic curve over 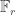 . Further refinements were done by Maurer and Wolf (CRYPTO 1996, SIAM J. Comput. 1999) and Muzereau-Smart-Vercauteren (LMS J. Comput. Math. 2004), Bentahar (IMA Cryptography and Coding 2005).
. Further refinements were done by Maurer and Wolf (CRYPTO 1996, SIAM J. Comput. 1999) and Muzereau-Smart-Vercauteren (LMS J. Comput. Math. 2004), Bentahar (IMA Cryptography and Coding 2005).![[a]P](https://s0.wp.com/latex.php?latex=%5Ba%5DP&bg=ffffff&fg=333333&s=0&c=20201002) and
and ![[b]P](https://s0.wp.com/latex.php?latex=%5Bb%5DP&bg=ffffff&fg=333333&s=0&c=20201002) one adds the points to compute
one adds the points to compute ![[a+b]P](https://s0.wp.com/latex.php?latex=%5Ba%2Bb%5DP&bg=ffffff&fg=333333&s=0&c=20201002) . Multiplications are hard: Given
. Multiplications are hard: Given  and
and  are. I refer you to Chapter 21 of
are. I refer you to Chapter 21 of ![[a^n]P](https://s0.wp.com/latex.php?latex=%5Ba%5En%5DP&bg=ffffff&fg=333333&s=0&c=20201002) from
from ![([a]P,[a]P)](https://s0.wp.com/latex.php?latex=%28%5Ba%5DP%2C%5Ba%5DP%29&bg=ffffff&fg=333333&s=0&c=20201002) to get
to get ![[a^2]P](https://s0.wp.com/latex.php?latex=%5Ba%5E2%5DP&bg=ffffff&fg=333333&s=0&c=20201002) . Then I can call the CDH oracle again on
. Then I can call the CDH oracle again on ![([a^2]P,[a^2]P)](https://s0.wp.com/latex.php?latex=%28%5Ba%5E2%5DP%2C%5Ba%5E2%5DP%29&bg=ffffff&fg=333333&s=0&c=20201002) to get
to get ![[a^4]P](https://s0.wp.com/latex.php?latex=%5Ba%5E4%5DP&bg=ffffff&fg=333333&s=0&c=20201002) etc. I need the CDH oracle to work on any chosen inputs
etc. I need the CDH oracle to work on any chosen inputs , and on input a point
, and on input a point ![[s]P](https://s0.wp.com/latex.php?latex=%5Bs%5DP&bg=ffffff&fg=333333&s=0&c=20201002) . One big difference between such oracles and a general CDH oracle is that I know how to implement such an oracle without solving DLP first.
. One big difference between such oracles and a general CDH oracle is that I know how to implement such an oracle without solving DLP first.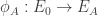 of degree
of degree 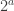 and
and  of degree
of degree 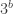 , together with some auxiliary points. Assume
, together with some auxiliary points. Assume 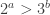 .
.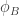 on points of order
on points of order 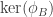 and SIDH is broken. (This is the goal of the torsion-point attacks by Petit et al, it is also the idea for the improvement to the original attack by Rémy Oudompheng and others that I mentioned above.) This is what Damien Robert’s attack does too.
and SIDH is broken. (This is the goal of the torsion-point attacks by Petit et al, it is also the idea for the improvement to the original attack by Rémy Oudompheng and others that I mentioned above.) This is what Damien Robert’s attack does too.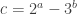 . Then we can write
. Then we can write  as a sum of four squares. In this post I will take the simpler case when all prime factors of the square-free part of
as a sum of four squares. In this post I will take the simpler case when all prime factors of the square-free part of 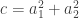 where
where 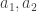 are integers. [Note added 15/8/2022 thanks to Daniel Bernstein: To do this we need to factor
are integers. [Note added 15/8/2022 thanks to Daniel Bernstein: To do this we need to factor 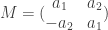 . Then
. Then 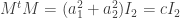 where
where  is the
is the  identity matrix. Hence
identity matrix. Hence  defines an isogeny
defines an isogeny 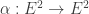 for any elliptic curve
for any elliptic curve ![\alpha(X,Y) = ( [a_1]X + [a_2]Y, [-a_2]X + [a_1] Y )](https://s0.wp.com/latex.php?latex=%5Calpha%28X%2CY%29+%3D+%28+%5Ba_1%5DX+%2B+%5Ba_2%5DY%2C+%5B-a_2%5DX+%2B+%5Ba_1%5D+Y+%29&bg=ffffff&fg=333333&s=0&c=20201002) . The dual isogeny
. The dual isogeny 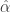 corresponds to the transpose
corresponds to the transpose 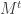 . We have
. We have ![\hat{\alpha}\alpha = [c]](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Calpha%7D%5Calpha+%3D+%5Bc%5D&bg=ffffff&fg=333333&s=0&c=20201002) as a map from
as a map from 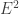 to itself. We will apply this map to both
to itself. We will apply this map to both 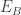 .
.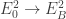 as
as 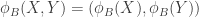 . Note that
. Note that  , since
, since 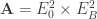 , by
, by 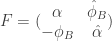 . The dual isogeny is
. The dual isogeny is 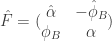 and one can check
and one can check 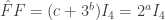 where
where 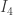 is the identity map (or identity matrix if you want to view these as matrices).
is the identity map (or identity matrix if you want to view these as matrices).![E_0[ 2^a ]](https://s0.wp.com/latex.php?latex=E_0%5B+2%5Ea+%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Since
. Since ![\hat{\phi}_B \phi_B = [ 3^b]](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Cphi%7D_B+%5Cphi_B+%3D+%5B+3%5Eb%5D&bg=ffffff&fg=333333&s=0&c=20201002) we can also compute how
we can also compute how 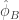 acts on
acts on ![E_B[ 2^a ]](https://s0.wp.com/latex.php?latex=E_B%5B+2%5Ea+%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Hence we can compute how
. Hence we can compute how ![{\bf A}[2^a]](https://s0.wp.com/latex.php?latex=%7B%5Cbf+A%7D%5B2%5Ea%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Since
. Since ![\ker(F) \subseteq {\bf A}[2^a]](https://s0.wp.com/latex.php?latex=%5Cker%28F%29+%5Csubseteq+%7B%5Cbf+A%7D%5B2%5Ea%5D&bg=ffffff&fg=333333&s=0&c=20201002) it means we compute
it means we compute  .
.![{\bf A}[ 3^b]](https://s0.wp.com/latex.php?latex=%7B%5Cbf+A%7D%5B+3%5Eb%5D&bg=ffffff&fg=333333&s=0&c=20201002) and hence compute
and hence compute ![E_0[ 3^b]](https://s0.wp.com/latex.php?latex=E_0%5B+3%5Eb%5D&bg=ffffff&fg=333333&s=0&c=20201002) and break SIDH.
and break SIDH.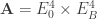 . I am not aware of any implementation of the attack as yet, but I look forward to seeing one. The attack can also be set up to compute the isogeny
. I am not aware of any implementation of the attack as yet, but I look forward to seeing one. The attack can also be set up to compute the isogeny 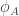 instead, simply by brute-forcing an extra small 3-power isogeny so that
instead, simply by brute-forcing an extra small 3-power isogeny so that 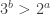 .
.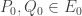 have order
have order 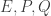 be given such that there exists an isogeny
be given such that there exists an isogeny  ,
, 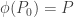 , and
, and 
 connected by 3-isogenies.
connected by 3-isogenies.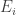 and hence eventually determines the private key. At step
and hence eventually determines the private key. At step  the attack does a brute-force search of all possible
the attack does a brute-force search of all possible 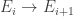 , and the magic ingredient is a gadget that shows which one is correct.
, and the magic ingredient is a gadget that shows which one is correct.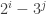 for various
for various 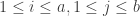 and it is not clear how to do this if we are not close to a curve with small discriminant complex multiplication. So one hope is that SIDH can be saved by choosing a base curve
and it is not clear how to do this if we are not close to a curve with small discriminant complex multiplication. So one hope is that SIDH can be saved by choosing a base curve 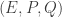 where
where 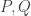 are points. The points
are points. The points 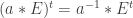 ) can be used to construct a two-round oblivious transfer (OT) scheme. The paper has a fully UC-secure 3-round version. In the live Q&A session, Lai announced that the paper has a “fixable bug” that means the fully secure version requires 4 rounds. Keep an eye on eprint for an updated version.
) can be used to construct a two-round oblivious transfer (OT) scheme. The paper has a fully UC-secure 3-round version. In the live Q&A session, Lai announced that the paper has a “fixable bug” that means the fully secure version requires 4 rounds. Keep an eye on eprint for an updated version. -NAF for Koblitz Curves Revisited” by Yu and Xu is about efficient discrete-log crypto using elliptic curves. Sadly there were technical problems during the live session and so Yu was unable to answer questions. Since
-NAF for Koblitz Curves Revisited” by Yu and Xu is about efficient discrete-log crypto using elliptic curves. Sadly there were technical problems during the live session and so Yu was unable to answer questions. Since 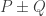 on Kohel’s
on Kohel’s 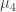 -model of elliptic curves, and by organising the precomputation stage for the window method more effectively. Combined, these methods allow to potentially go as far as windows of length
-model of elliptic curves, and by organising the precomputation stage for the window method more effectively. Combined, these methods allow to potentially go as far as windows of length 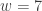 .
. such that
such that  and
and 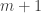 are very smooth.
are very smooth.