In February 2016, Kim and Barbulescu posted on eprint a merged version of two earlier pre-prints ([eprint:Kim15] and [eprint:Barbulescu15]). This preprint is about computing discrete logarithms (DL) in finite fields and presents a new variant of the Number Field Sieve algorithm (NFS) for finite fields 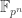 . The Number Field Sieve algorithm can be applied to compute discrete logarithms in any finite field of medium to large characteristic . Kim and Barbulescu improve its asymptotic complexity for finite fields where
. The Number Field Sieve algorithm can be applied to compute discrete logarithms in any finite field of medium to large characteristic . Kim and Barbulescu improve its asymptotic complexity for finite fields where  is composite, and one of the factors is of an appropriate size. The paper restricts to non-prime-power extension degree (e.g.
is composite, and one of the factors is of an appropriate size. The paper restricts to non-prime-power extension degree (e.g.  or
or 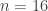 is not targeted) but a generalization to any non-prime is quite easy to obtain. Typical finite fields that are target groups in pairing-based cryptography are affected, such as
is not targeted) but a generalization to any non-prime is quite easy to obtain. Typical finite fields that are target groups in pairing-based cryptography are affected, such as 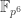 and
and 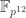 .
.
Pairing-based cryptography
A pairing is a bilinear map defined over an elliptic curve. It outputs a value in a finite field. This is commonly expressed as 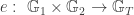 where
where  and
and 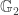 are two (distinct) prime order subgroups of an elliptic curve, and
are two (distinct) prime order subgroups of an elliptic curve, and  is the target group, of same prime order. More precisely, we have
is the target group, of same prime order. More precisely, we have
![\begin{array}{lccccc} e: & \mathbb{G}_1 & \times & \mathbb{G}_2 & \to & \mathbb{G}_T \\ & \cap & & \cap & & \cap \\ & E(\mathbb{F}_p)[\ell] & & E(\mathbb{F}_{p^n})[\ell] & & \boldsymbol{\mu}_{\ell} \subset \mathbb{F}_{p^n}^{*}\\ \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Blccccc%7D++++e%3A+%26+%5Cmathbb%7BG%7D_1+%26+%5Ctimes+%26+%5Cmathbb%7BG%7D_2+%26+%5Cto+%26+%5Cmathbb%7BG%7D_T+%5C%5C+++%26+%5Ccap+%26++++++++%26+%5Ccap+%26+++++%26+%5Ccap++%5C%5C++%26+E%28%5Cmathbb%7BF%7D_p%29%5B%5Cell%5D+%26++%26+E%28%5Cmathbb%7BF%7D_%7Bp%5En%7D%29%5B%5Cell%5D+%26+%26+%5Cboldsymbol%7B%5Cmu%7D_%7B%5Cell%7D++%5Csubset+%5Cmathbb%7BF%7D_%7Bp%5En%7D%5E%7B%2A%7D%5C%5C++%5Cend%7Barray%7D&bg=ffffff&fg=333333&s=0&c=20201002)
where  is the cyclotomic subgroup of
is the cyclotomic subgroup of  , i.e. the subgroup of
, i.e. the subgroup of  -th roots of unity:
-th roots of unity: 
The use of pairings as a constructive tool in cryptography had some premices in 1999 and started to be used in 2000. Its security relies on the intractability of the discrete logarithm problem on the elliptic curve (i.e. in and ) and in the finite field (i.e. in ).
The expected running-time of a discrete logarithm computation on an elliptic curve and in a finite field is not the same: this is 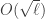 in the group of points
in the group of points ![E(\mathbb{F}_p)[\ell]](https://s0.wp.com/latex.php?latex=E%28%5Cmathbb%7BF%7D_p%29%5B%5Cell%5D&bg=ffffff&fg=333333&s=0&c=20201002) , and this is
, and this is ![L_{p^n}[1/3, c]](https://s0.wp.com/latex.php?latex=L_%7Bp%5En%7D%5B1%2F3%2C+c%5D&bg=ffffff&fg=333333&s=0&c=20201002) in a finite field , where
in a finite field , where  is the notation
is the notation ![L_{p^n}[1/3, c] = \exp\left( (c+o(1)) (\log p^n)^{1/3} (\log \log p^n)^{2/3} \right) ~.](https://s0.wp.com/latex.php?latex=L_%7Bp%5En%7D%5B1%2F3%2C+c%5D+%3D+%5Cexp%5Cleft%28+%28c%2Bo%281%29%29+%28%5Clog+p%5En%29%5E%7B1%2F3%7D+%28%5Clog+%5Clog+++p%5En%29%5E%7B2%2F3%7D+%5Cright%29+%7E.&bg=ffffff&fg=333333&s=0&c=20201002) The asymptotic complexity in the finite field depends on the total size
The asymptotic complexity in the finite field depends on the total size 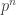 of the finite field. It means that we can do cryptography in an order subgroup of , whenever is large enough.
of the finite field. It means that we can do cryptography in an order subgroup of , whenever is large enough.
Small, medium and large characteristic.
The finite fields are commonly divided into three cases, depending on the size of the prime  (the finite field characteristic) compared to the extension degree . Each of the three cases has its own index calculus variant, and the most appropriate variant that applies qualifies the characteristic (as small, large or medium):
(the finite field characteristic) compared to the extension degree . Each of the three cases has its own index calculus variant, and the most appropriate variant that applies qualifies the characteristic (as small, large or medium):
- small characteristic: one uses the function field sieve (FFS) algorithm, and the quasi-polynomial-time algorithm when the extension degree is suitable for that (i.e. smooth enough);
- medium characteristic: one uses the NFS-HD algorithm. This is the High Degree variant of the Number Field Sieve (NFS) algorithm. The elements involved in the relation collection are of higher degree compared to the regular NFS algorithm.
- large characteristic: one uses the Number Field Sieve algorithm.
Each variant (QPA, FFS, NFS-HD and NFS) has a different asymptotic complexity.
Quasi Polynomial Time algorithm for small characteristic finite fields
Small characteristic finite fields such as 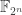 and
and  where is composite are broken for pairing-based cryptography with the QPA algorithm (see this blog post).
where is composite are broken for pairing-based cryptography with the QPA algorithm (see this blog post).
It does not mean that supersingular curves are broken but it means that the pairing-friendly curves in small characteristic are broken, and only supersingular pairing-friendly curves were available in small characteristic. There exist supersingular pairing-friendly curves in large characteristic which are still safe, if the finite field is chosen of large enough size.
How it affects pairing-based cryptography.
It was assumed in order to set up the key-sizes of pairing-based cryptography that computing a discrete logarithm in any finite field of medium to large characteristic is of same difficulty at least as computing a discrete logarithm in a prime field of the same total size. The key-size were chosen according to the complexity formula ![L_{p^n}[1/3, (64/9)^{1/3} = 1.923]](https://s0.wp.com/latex.php?latex=L_%7Bp%5En%7D%5B1%2F3%2C+%2864%2F9%29%5E%7B1%2F3%7D+%3D+1.923%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.
The finite fields targeted by this new variant are of the form , where is composite (e.g. 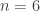 ,
, 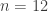 ) and there exists a small factor
) and there exists a small factor  of (e.g. 2 or 3 for 6 and 12). In that case, this is possible to consider both the finite field and the two number fields involved in the NFS algorithm as a tower of an extension of degree
of (e.g. 2 or 3 for 6 and 12). In that case, this is possible to consider both the finite field and the two number fields involved in the NFS algorithm as a tower of an extension of degree  on top of an extension of degree . With this representation, combined with previously known polynomial selection methods, the norm of the elements involved in the relation collection step (second step of the NFS algorithm) is much smaller. This provides an important speed-up of all the algorithm and decreases the asymptotic complexity below the assumed
on top of an extension of degree . With this representation, combined with previously known polynomial selection methods, the norm of the elements involved in the relation collection step (second step of the NFS algorithm) is much smaller. This provides an important speed-up of all the algorithm and decreases the asymptotic complexity below the assumed ![L_{p^n}[1/3, 1.92]](https://s0.wp.com/latex.php?latex=L_%7Bp%5En%7D%5B1%2F3%2C+1.92%5D&bg=ffffff&fg=333333&s=0&c=20201002) complexity. That is why in certain cases, the key sizes should be enlarged.
complexity. That is why in certain cases, the key sizes should be enlarged.
Outline
It start with a brief summary on the previous state of the art in DL computation in , then the Kim–Barbulescu variant is sketched, and a possible key-size update in pairing-based cryptography is discussed. This is not reasonnable at the time of writting to propose practical key-size update, but we can discuss about an estimate, based on the new asymptotic complexities.
The Number Field Sieve algorithm (NFS)
The NFS algorithm to compute discrete logarithms applies to finite fields  where (the characteristic) is of medium to large size compared to the total size of the finite field. This is measured asymptotically as
where (the characteristic) is of medium to large size compared to the total size of the finite field. This is measured asymptotically as ![p \geq L_{p^n}[\alpha, c]](https://s0.wp.com/latex.php?latex=p+%5Cgeq+L_%7Bp%5En%7D%5B%5Calpha%2C+c%5D&bg=ffffff&fg=333333&s=0&c=20201002) where
where  and the notation is defined as
and the notation is defined as ![L_{p^n}[1/3, c] = \exp\left( (c+o(1)) (\log p^n)^{1/3} (\log \log p^n)^{2/3} \right) ~.](https://s0.wp.com/latex.php?latex=L_%7Bp%5En%7D%5B1%2F3%2C+c%5D+%3D+%5Cexp%5Cleft%28+%28c%2Bo%281%29%29+%28%5Clog+p%5En%29%5E%7B1%2F3%7D+%28%5Clog+%5Clog+p%5En%29%5E%7B2%2F3%7D+%5Cright%29+%7E.&bg=ffffff&fg=333333&s=0&c=20201002)
Since in pairing-based cryptography, small characteristic is restricted to and , we can simplify the situation and say that the NFS algorithm and its variants apply to all the non-small-characteristic finite fields used in pairing-based cryptography. The Kim–Barbulescu pre-print contains two new asymptotic complexities for computing discrete logarithms in such finite fields. Prime fields 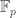 are not affected by this new algorithm. The finite fields used in pairing-based cryptography that are affected are and for example.
are not affected by this new algorithm. The finite fields used in pairing-based cryptography that are affected are and for example.
The NFS algorithm is made of four steps:
- polynomial selection,
- relation colection,
- linear algebra,
- individual discrete logarithm.
The Kim–Barbulescu improvement presents a new polynomial selection that combines the Tower-NFS construction (TNFS) [AC:BarGauKle15] with the Conjugation technique [EC:BGGM15]. This leads to a better asymptotic complexity of the algorithm. The polynomial selection determines the expected running time of the algorithm. The idea of NFS is to work in a number field instead of a finite field, so that a notion of small elements exists as well as a factorization of the elements into prime ideals. This is not possible in a finite field .
Take as an example the prime  3141592653589793238462643383589
3141592653589793238462643383589  as in Kim Barbulescu eprint and consider . The order of the cyclotomic subgroup is
as in Kim Barbulescu eprint and consider . The order of the cyclotomic subgroup is  and the 194-bit prime
and the 194-bit prime  13688771707474838583681679614171480268081711303057164980773 is the largest prime divisor of
13688771707474838583681679614171480268081711303057164980773 is the largest prime divisor of  . Since
. Since  , one can construct a Kummer extension
, one can construct a Kummer extension ![\mathbb{F}_p[x]/(x^6+2)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BF%7D_p%5Bx%5D%2F%28x%5E6%2B2%29&bg=ffffff&fg=333333&s=0&c=20201002) , where
, where 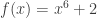 is irreducible modulo . Then to run NFS, the idea of Joux, Lercier, Smart and Vercauteren in 2006 [JLSV06] was to use
is irreducible modulo . Then to run NFS, the idea of Joux, Lercier, Smart and Vercauteren in 2006 [JLSV06] was to use ![\mathbb{Z}[x]/(f(x))](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5Bx%5D%2F%28f%28x%29%29&bg=ffffff&fg=333333&s=0&c=20201002) as the first ring, and
as the first ring, and ![\mathbb{Z}[x]/(g(x)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5Bx%5D%2F%28g%28x%29&bg=ffffff&fg=333333&s=0&c=20201002) where
where  as the second one to collect relations in NFS. Take the element
as the second one to collect relations in NFS. Take the element  . Its norm in
. Its norm in ![\mathbb{Z}[\alpha_f] = \mathbb{Z}[x]/(f(x))](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5B%5Calpha_f%5D+%3D+%5Cmathbb%7BZ%7D%5Bx%5D%2F%28f%28x%29%29&bg=ffffff&fg=333333&s=0&c=20201002) is 122-bit long. Its norm in
is 122-bit long. Its norm in ![\mathbb{Z}[\alpha_g] = \mathbb{Z}[x]/(g(x))](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5B%5Calpha_g%5D+%3D+%5Cmathbb%7BZ%7D%5Bx%5D%2F%28g%28x%29%29&bg=ffffff&fg=333333&s=0&c=20201002) is 322-bit long, the total is 444 bits.
is 322-bit long, the total is 444 bits.
Why do we need two sides (the two rings and ![\mathbb{Z}[x]/(g(x))](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5Bx%5D%2F%28g%28x%29%29&bg=ffffff&fg=333333&s=0&c=20201002) )? Because when mapping these two elements from and to , one maps
)? Because when mapping these two elements from and to , one maps 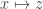 since
since 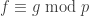 , so that
, so that  and at the same time,
and at the same time,  is mapped to the same element. What is the purpose of all of this? We will obtain a different factorization into prime ideals in each ring, so that we will get a non-trivial relation when mapping each side to . Now the game is to define polynomials
is mapped to the same element. What is the purpose of all of this? We will obtain a different factorization into prime ideals in each ring, so that we will get a non-trivial relation when mapping each side to . Now the game is to define polynomials  and
and  such that the norm is as low as possible, so that the probability that an element will factor into small prime ideals is high.
such that the norm is as low as possible, so that the probability that an element will factor into small prime ideals is high.
A few new polynomial selection methods were proposed since 2006, to reduce this norm, hence improving the asymptotic complexity of the NFS algorithm. In practice, each finite field is a case study, and the method with the best asymptotic running-time will not obviously gives the smallest norms in practice. That is why cryptanalysts compare the norm bounds in addition to comparing the asymptotic complexity. This is done in Table 5 and Fig. 2 of the Kim–Barbulescu pre-print.
What is the key-idea of the Kim–Barbulescu method? It combines two previous techniques: the Tower-NFS variant [AC:BarGauKle15] and the Conjugation polynomial selection method [EC:BGGM15]. Moreover, it exploits the fact that is composite. Sarkar and Sigh started in this direction in [EC:SarSin16] and obtained a smaller norm estimate (the asymptotic complexity was not affected significatively). We mention that few days ago, Sarkar and Singh combined the Kim–Barbulescu technique with their polynomial selection method [EPRINT:SarSin16].
Here is a list of the various polynomial selection methods for finite fields .
- the Joux–Lercier–Smart–Vercauteren method that applies to medium-characteristic finite fields, a.k.a. JLSV1, whose asymptotic complexity is
![L_{p^n}[1/3, (128/9)^{1/3} = 2.42]](https://s0.wp.com/latex.php?latex=L_%7Bp%5En%7D%5B1%2F3%2C+%28128%2F9%29%5E%7B1%2F3%7D+%3D+2.42%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.
- the Conjugation method that applies to medium-characteristic finite fields, whose asymptotic complexity is
![L_{p^n}[1/3, (32/3)^{1/3} = 2.201]](https://s0.wp.com/latex.php?latex=L_%7Bp%5En%7D%5B1%2F3%2C+%2832%2F3%29%5E%7B1%2F3%7D+%3D+2.201%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.
- the JLSV2 method that applies to large-characteristic finite fields, whose asymptotic complexity is .
- the generalized Joux–Lercier (GJL) method that applies to large-characteristic finite fields, whose asymptotic complexity is .
- the Sarkar–Singh method that allows a trade-off between the GJL and the Conjugation method when is composite.
Back to our example, the Kim–Barbulescu technique would define polynomials such as
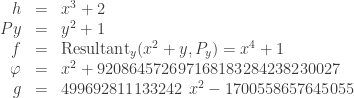
In this case, the elements involved in the relation collection step are of the form  . They have six coefficients. in order to enumerate a set of same global size
. They have six coefficients. in order to enumerate a set of same global size 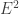 where
where  , one takes
, one takes  . The norm of
. The norm of  is 135.6 bit long, the norm of
is 135.6 bit long, the norm of  is 216.6 bit long, for a total of 352.2 bits. This is 92 bits less than the 444 bits obtained with the former JLSV technique.
is 216.6 bit long, for a total of 352.2 bits. This is 92 bits less than the 444 bits obtained with the former JLSV technique.
Why the norm is smaller.
The norm computed in the number fields depends on the coefficient size and the degree of the polynomials defining the number fields, and on the degree and coefficient size of the element whose norm is computed.
With the Kim–Barbulescu technique, the norm is computed recursively from  to
to  then from to
then from to 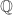 . The norm formula depends on the degree of the element and since this element is of degree 1 in , its norm will be as low as possible. Then in , the element is of degree (at most)
. The norm formula depends on the degree of the element and since this element is of degree 1 in , its norm will be as low as possible. Then in , the element is of degree (at most)  but this does not increase its norm since the coefficients of
but this does not increase its norm since the coefficients of  are tiny (a norm bound is
are tiny (a norm bound is  , and
, and  will be very small).
will be very small).
Why it changes the asymptotic complexity.
The asymptotic complexity is reduced (contrary to the Sarkar–Singh method) because the norm formula is reduced not only in practice but also in the asymptotic formula. To do so, the parameters should be tuned very tightly. In the large characteristic case,  should stay quite small:
should stay quite small: 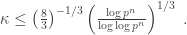 For of 608 bits as in the example, the numerical value is
For of 608 bits as in the example, the numerical value is  . Kim and Barbulescu took
. Kim and Barbulescu took  . In fact,
. In fact,  should be as small as possible, so that one can collect relations over elements of any degree in
should be as small as possible, so that one can collect relations over elements of any degree in  , but always degree 1 in
, but always degree 1 in  . The smallest possible value is when is even.
. The smallest possible value is when is even.
For the classical BN curve example where  is a 3072-bit prime power, the bound is
is a 3072-bit prime power, the bound is  .
.
Special-NFS variant when is given by a polynomial.
For prime fields where has a special form, the Special-NFS algorithm may apply. Its complexity is ![L_{p}[1/3, (32/9)^{1/3} = 1.526]](https://s0.wp.com/latex.php?latex=L_%7Bp%7D%5B1%2F3%2C+%2832%2F9%29%5E%7B1%2F3%7D+%3D+1.526%5D&bg=ffffff&fg=333333&s=0&c=20201002) . For extension fields , where is obtained by evaluating a polynomial of degree at a given value, e.g.
. For extension fields , where is obtained by evaluating a polynomial of degree at a given value, e.g.  for BN curves, Joux and Pierrot [PAIRING:JouPie13] proposed a dedicated polynomial selection method such that the NFS algorithm has an exptected running-time of
for BN curves, Joux and Pierrot [PAIRING:JouPie13] proposed a dedicated polynomial selection method such that the NFS algorithm has an exptected running-time of
-
![L_{p^n}\left[1/3, \left(\frac{d+1}{d}\frac{64}{9}\right)^{1/3}\right]](https://s0.wp.com/latex.php?latex=L_%7Bp%5En%7D%5Cleft%5B1%2F3%2C+%5Cleft%28%5Cfrac%7Bd%2B1%7D%7Bd%7D%5Cfrac%7B64%7D%7B9%7D%5Cright%29%5E%7B1%2F3%7D%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002) in medium characteristic, where
in medium characteristic, where ![p = L_{p^n}[\alpha_p, c_p]](https://s0.wp.com/latex.php?latex=p+%3D+L_%7Bp%5En%7D%5B%5Calpha_p%2C+c_p%5D&bg=ffffff&fg=333333&s=0&c=20201002) and
and  ;
;
-
![L_{p^n}\left[1/3, \left(\frac{32}{9}\right)^{1/3}\right]](https://s0.wp.com/latex.php?latex=L_%7Bp%5En%7D%5Cleft%5B1%2F3%2C+%5Cleft%28%5Cfrac%7B32%7D%7B9%7D%5Cright%29%5E%7B1%2F3%7D%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002) in large characteristic, where and
in large characteristic, where and  and moreover satisfies
and moreover satisfies  ;
;
- in prime fields and tiny extension degree fields, where
![p = L_{p^n}[1, c_p]](https://s0.wp.com/latex.php?latex=p+%3D+L_%7Bp%5En%7D%5B1%2C+c_p%5D&bg=ffffff&fg=333333&s=0&c=20201002) and moreover satisfies .
and moreover satisfies .
The Kim–barbulescu method combines the TNFS method and the Joux–Pierrot method to obtain a ![L_{p^n}[1/3, (32/9)^{1/3} = 1.526]](https://s0.wp.com/latex.php?latex=L_%7Bp%5En%7D%5B1%2F3%2C+%2832%2F9%29%5E%7B1%2F3%7D+%3D+1.526%5D&bg=ffffff&fg=333333&s=0&c=20201002) asymptotic complexity in the medium-characteristic case.
asymptotic complexity in the medium-characteristic case.
Discussion on key-size update
This new attack reduces the asymptotic complexity of the NFS algorithm to compute DL in , which contains the target group of pairings. The recommended sizes of were computed assuming that the asymptotic complexity is ![L_{p^n}[1/3, 1.923]](https://s0.wp.com/latex.php?latex=L_%7Bp%5En%7D%5B1%2F3%2C+1.923%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Since the new complexity is below this bound, the key sizes should be enlarged. The smallest asymptotic complexity that Kim and Barbulescu obtain is for a combination of Extended-TNFS and Special-NFS. They obtain when the prime is given by a polynomial of degree and when is composite,
. Since the new complexity is below this bound, the key sizes should be enlarged. The smallest asymptotic complexity that Kim and Barbulescu obtain is for a combination of Extended-TNFS and Special-NFS. They obtain when the prime is given by a polynomial of degree and when is composite,  , and
, and  satisfies an appropriate bound. In that case, it means that the size of should be roughly doubled asymptotically.
satisfies an appropriate bound. In that case, it means that the size of should be roughly doubled asymptotically.
Comparison with NFS in prime fields  .
.
In order to provide a first comparison of the expected running-time of the NFS algorithm in finite fields and prime fields of same total size, one can compare the size of the norms involved in the relation collection. We took the example of 608 bits (183 decimal digits), and consider a prime field of 608 bits for comparison. The Joux–Lercier method [MathComp:JouLer03] generates two polynomials and of degree 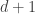 and and coefficient size
and and coefficient size  ,
, 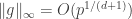 . We take
. We take  , where
, where  . We obtain
. We obtain  . We take
. We take 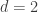 . The choice
. The choice 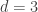 would end to slightly larger norms (5 to 10 bit larger).
would end to slightly larger norms (5 to 10 bit larger).
The polynomials and would be of degree 3 and 2, and the coefficient size of would be  of 203 bits. The bound
of 203 bits. The bound  in the relation collection would be approximately
in the relation collection would be approximately 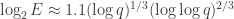 (in theory
(in theory ![L_p[1/3, \beta=(8/9)^{1/3}]](https://s0.wp.com/latex.php?latex=L_p%5B1%2F3%2C+%5Cbeta%3D%288%2F9%29%5E%7B1%2F3%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002) ) of 27.36 bits (cado-nfs) up to 30 bits (Kim–Barbulescu estimate). The norms of the elements would be
) of 27.36 bits (cado-nfs) up to 30 bits (Kim–Barbulescu estimate). The norms of the elements would be  of 341 bits (
of 341 bits ( ) to 354 bits (
) to 354 bits ( ). Kim and Barbulescu obtain a norm of 330 bits for [Example 1]. It means that computing a discrete logarithm in compared to both of 608 bits would be easier in .
). Kim and Barbulescu obtain a norm of 330 bits for [Example 1]. It means that computing a discrete logarithm in compared to both of 608 bits would be easier in .
We can do the same analysis for of 3072 bits and this starts to be a complete mess. The Joux–Lercier method for a prime field  of 3072 bits would take polynomials of degree and the norms would be of 1243 bits. The Kim–Barbulescu technique (ExTNFS) with Conjugation in of 3072 bits would involve norms of 696 bits in average. If moreover we consider a BN-prime given by a polynomial of degree 4, and take
of 3072 bits would take polynomials of degree and the norms would be of 1243 bits. The Kim–Barbulescu technique (ExTNFS) with Conjugation in of 3072 bits would involve norms of 696 bits in average. If moreover we consider a BN-prime given by a polynomial of degree 4, and take  and
and 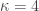 , the norms would be of 713 bits in average. This is also what [Fig. 3] shows: the cross-over point betweeen ExTNFS-Conj (of asymptotic complexity ) and Special ExTNFS (of asymptotic complexity
, the norms would be of 713 bits in average. This is also what [Fig. 3] shows: the cross-over point betweeen ExTNFS-Conj (of asymptotic complexity ) and Special ExTNFS (of asymptotic complexity ![L_{p^n}[1/3, 1.52]](https://s0.wp.com/latex.php?latex=L_%7Bp%5En%7D%5B1%2F3%2C+1.52%5D&bg=ffffff&fg=333333&s=0&c=20201002) ) is above 4250 bits.
) is above 4250 bits.
Security level estimates and key-sizes.
[Edited May 3 thanks to P.S.L.M. B. comments]
What would be the actual security level of a BN curve with of 256 bits and of 3072 bits? At the moment, the best attack would use a combination of Extended TNFS with the Joux–Pierrot polynomial selection for special primes, or the ExTNFS with Conjugation. We give in the following table a rough estimate of the improvement. Evaluating the asymptotic complexity for a given finite field size does no provide the number of bits of security but could give a (theoretical) hint on the improvements of the Kim–Barbulescu technique. This table can only say that the former 256-bit prime BN curve should be changed into a 448 up to 512-bit prime BN-curve.
This is a rough and theoretical estimate. This can only says that a new low bound on the size of BN-like to achieve a 128-bit security level would be at least 5376 bits ( of 448 bits).
[edited June 8th thanks to T. Kim comments. In the medium prime case, the best complexity of Extended TNFS is ![L_{p^n}[1/3, 1.74]](https://s0.wp.com/latex.php?latex=L_%7Bp%5En%7D%5B1%2F3%2C+1.74%5D&bg=ffffff&fg=333333&s=0&c=20201002) when is composite. ]
when is composite. ]
![\begin{array}{|c|c|c|c|c|c|c|} \hline \log_2 p & n & \log_2 q & \begin{array}{@{}c@{}} \mbox{Joux--Pierrot NFS}\\ d=4, L_{p^n}[1/3, 2.07] \end{array} & \begin{array}{@{}c@{}} \\ L_{p^n}[1/3, 1.92] \end{array} & \begin{array}{@{}c@{}} \mbox{Extended TNFS}\\ L_{p^n}[1/3, 1.74] \end{array} & \begin{array}{@{}c@{}} \mbox{Special Extended TNFS}\\ L_{p^n}[1/3, 1.53] \end{array} \\ \hline 256 & 12 & 3072 & \approx 2^{149-\delta_1} & \approx 2^{139-\delta_2} & \approx 2^{126-\delta_3} & \approx 2^{110-\delta_4} \\ \hline 384 & 12 & 4608 & \approx 2^{177-\delta_1} & \approx 2^{164-\delta_2} & \approx 2^{149-\delta_3} & \approx 2^{130-\delta_4} \\ \hline 448 & 12 & 5376 & \approx 2^{189-\delta_1} & \approx 2^{175-\delta_2} & \approx 2^{159-\delta_3} & \approx 2^{139-\delta_4} \\ \hline 512 & 12 & 6144 & \approx 2^{199-\delta_1} & \approx 2^{185-\delta_2} & \approx 2^{168-\delta_3} & \approx 2^{147-\delta_4} \\ \hline \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7B%7Cc%7Cc%7Cc%7Cc%7Cc%7Cc%7Cc%7C%7D++%5Chline+%5Clog_2+p+%26++n++%26+%5Clog_2+q++%26+%5Cbegin%7Barray%7D%7B%40%7B%7Dc%40%7B%7D%7D+%5Cmbox%7BJoux--Pierrot+NFS%7D%5C%5C+d%3D4%2C+L_%7Bp%5En%7D%5B1%2F3%2C+2.07%5D+%5Cend%7Barray%7D++++%26+%5Cbegin%7Barray%7D%7B%40%7B%7Dc%40%7B%7D%7D+%5C%5C+L_%7Bp%5En%7D%5B1%2F3%2C+1.92%5D++%5Cend%7Barray%7D++++%26+%5Cbegin%7Barray%7D%7B%40%7B%7Dc%40%7B%7D%7D+%5Cmbox%7BExtended+TNFS%7D%5C%5C+L_%7Bp%5En%7D%5B1%2F3%2C+1.74%5D++%5Cend%7Barray%7D+++++%26+%5Cbegin%7Barray%7D%7B%40%7B%7Dc%40%7B%7D%7D+%5Cmbox%7BSpecial+Extended+TNFS%7D%5C%5C+L_%7Bp%5En%7D%5B1%2F3%2C+1.53%5D+%5Cend%7Barray%7D+%5C%5C+++%5Chline+++256+++%26++12+%26++3072+++%26+%5Capprox+2%5E%7B149-%5Cdelta_1%7D+%26++%5Capprox+2%5E%7B139-%5Cdelta_2%7D+%26+%5Capprox+2%5E%7B126-%5Cdelta_3%7D+%26+%5Capprox+2%5E%7B110-%5Cdelta_4%7D+%5C%5C++%5Chline+++384+++%26++12+%26++4608+++%26+%5Capprox+2%5E%7B177-%5Cdelta_1%7D+%26++%5Capprox+2%5E%7B164-%5Cdelta_2%7D+%26+%5Capprox+2%5E%7B149-%5Cdelta_3%7D+%26+%5Capprox+2%5E%7B130-%5Cdelta_4%7D+%5C%5C++%5Chline+++448+++%26++12+%26++5376+++%26+%5Capprox+2%5E%7B189-%5Cdelta_1%7D+%26++%5Capprox+2%5E%7B175-%5Cdelta_2%7D+%26+%5Capprox+2%5E%7B159-%5Cdelta_3%7D+%26+%5Capprox+2%5E%7B139-%5Cdelta_4%7D+%5C%5C++%5Chline+++512+++%26++12+%26++6144+++%26+%5Capprox+2%5E%7B199-%5Cdelta_1%7D+%26++%5Capprox+2%5E%7B185-%5Cdelta_2%7D+%26+%5Capprox+2%5E%7B168-%5Cdelta_3%7D+%26+%5Capprox+2%5E%7B147-%5Cdelta_4%7D+%5C%5C++%5Chline++%5Cend%7Barray%7D&bg=ffffff&fg=333333&s=0&c=20201002)
To obtain a key size according to a security level, a value 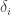 is required, which is not known. The order of magnitude of this is usually of a dozen. A 4608-bit field (corresponding for Barreto-Naehrig curves to of 384 bits) might not be large enough to achieve a 128-bit security level.
is required, which is not known. The order of magnitude of this is usually of a dozen. A 4608-bit field (corresponding for Barreto-Naehrig curves to of 384 bits) might not be large enough to achieve a 128-bit security level.
Alternative choices of pairing-friendly curves.
Few days ago, Chatterjee, Menezes and Rodriguez-Henriquez proposed to use embedding degree one curves as a safe alternative for pairing-based cryptography. However in these constructions, the prime is given by a polynomial of degree 2. It is not known what is the most secure: a prime field with given by a polynomial of degree 2 or a supersingular curve with 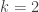 (or even a MNT curve with
(or even a MNT curve with 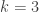 ).
).
Another way would be to use generic curves of embedding degree  or
or  , generated with the Cocks-Pinch method, so that no one of the recent attacks can apply. In any case the pairing computation would be much less efficient than previously with the BN curves and of 256 bits. Such low embedding degree curves were used at the beginning of pairing implementation, e.g. [CT-RSA:Scott05], [ICISC:ChaSarBar04].
, generated with the Cocks-Pinch method, so that no one of the recent attacks can apply. In any case the pairing computation would be much less efficient than previously with the BN curves and of 256 bits. Such low embedding degree curves were used at the beginning of pairing implementation, e.g. [CT-RSA:Scott05], [ICISC:ChaSarBar04].
Aurore Guillevic.


I think there are some typos around the paragraph that reads “This is a rough and theoretical estimate.” The table (which I checked) indicates that 128-bit security needs 384 bits BN curves, not 448 or 512. Also, the text there sounds a little strange (copy&paste&modify from previous paragraph, maybe?)
This is not easy to extrapolate key-sizes according to an asymptotic formula. The main issue with the NFS-like asymptotic formulas is the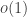 in the exponent, that hides all the polynomial factors. That is why this is not enough to compute a key-size only according to a formula such as
in the exponent, that hides all the polynomial factors. That is why this is not enough to compute a key-size only according to a formula such as ![L_{p^n}[1/3, c]](https://s0.wp.com/latex.php?latex=L_%7Bp%5En%7D%5B1%2F3%2C+c%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.![L_{p^n}[1/3, c]](https://s0.wp.com/latex.php?latex=L_%7Bp%5En%7D%5B1%2F3%2C+c%5D&bg=ffffff&fg=333333&s=0&c=20201002) and a constant obtained by a real-life computational record, to calibrate the asymptotic formula. This can be done for prime fields:
and a constant obtained by a real-life computational record, to calibrate the asymptotic formula. This can be done for prime fields:
To estimate a key size, we need the asymptotic formula
The last DL record computation in a prime field was in 2014, in a 595-bit prime field.
[BGIJT14]
Assuming that the computational effort was of approximately , we can calibrate the asymptotic formula accordingly. The asymptotic complexity is
, we can calibrate the asymptotic formula accordingly. The asymptotic complexity is ![L_{p}[1/3, (64/9)^(1/3)]](https://s0.wp.com/latex.php?latex=L_%7Bp%7D%5B1%2F3%2C+%2864%2F9%29%5E%281%2F3%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) . One needs to find a constant
. One needs to find a constant  such that
such that ![C L_{p}[1/3, (64/9)^(1/3)] = 2^{65}](https://s0.wp.com/latex.php?latex=C++L_%7Bp%7D%5B1%2F3%2C+%2864%2F9%29%5E%281%2F3%29%5D+%3D+2%5E%7B65%7D&bg=ffffff&fg=333333&s=0&c=20201002) where
where  bits. This is
bits. This is  . Then an extrapolation is possible.
. Then an extrapolation is possible.
There is no such real-life record computation available to calibrate the asymptotic formula of the new Kim–Barbulescu paper, and that is why a tight recommendation is not given.
Of course this is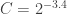 .
.
What I’m saying is that your *text* claims 448-bit curves for 128-bit security, yet your *table* reports ~130-bit security for 384-bit curves.
This is too early to claim any key size for a given security level. We really need a record computation.
The table was edited. Thanks.
“The asymptotic complexity is reduced (contrary to the Sarkar–Singh method) because the norm formula is reduced not only in practice but also in the asymptotic formula.”
It may be worth clarifying that this is “contrary to” the original Sarkar–Singh method. If I understand correctly, the Sarkar–Singh method combined with Kim–Barbulescu does give an asymptotic improvement, and is currently the best algorithm. (I’m assuming it can be applied to the “special extended” case as well.)
Zcash (https://z.cash) had been planning to use a BN128 curve, and we’re currently trying to reassess what curve we will need in light of this attack: https://github.com/zcash/zcash/issues/714
Besides asymptotic complexity are the concrete constants in these algorithms small? Are there experimental results? e.g. what is the largest p such that someone has found a DL in F_p^12?
There is a lot more discussion about the practical impact of these results in the recent paper “Challenges with Assessing the Impact of NFS Advances on the Security of Pairing-based Cryptography” by Alfred Menezes, Palash Sarkar and Shashank Singh.
http://eprint.iacr.org/2016/1102
Thanks for that great pointer! Perhaps you could help me.
I’m looking at Table 4, and it talks about the num of bits p needs for a certain security level with or without ignoring constants.
For example it says for BN curves with n=12, when not ignoring constants, 256 bits in p is enough for 128 bit security.
Isn’t *that* the relevant number?
Why also write the number that ignores the constants?
Pingback: Technical developments in Cryptography: 2016 in Review ~ MCJ™
The estimates without the constants should be considered to be conservative estimates. See the first paragraph of Section 6.3 of our updated paper at http://eprint.iacr.org/2016/1102.
Pingback: Recent work on pairing inversion | ellipticnews